When Hadoop tools disagree with each other
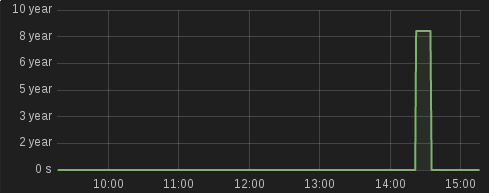
The above graph from our data warehouse system was recently tweeted out, and got some amused responses about 2007 wanting its data back. But there’s actually a good story here, and a chance to look at Hadoop’s dirty secrets.
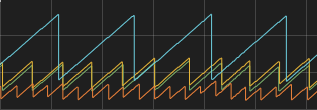
Picture if you will a graph showing the time between now and the last record to be inserted into a table (similar to the one above). For a regular batch operation, you’d expect a nice saw tooth graph - slowly ramping up for 20 minutes, followed by a sharp drop to around 5 minutes. The minimum value is the time it takes for the job to run, the height of the graph is how long between runs. The graph above shows different batch operations, with different timings.

But if we zoom in on that flat portion of the first graph, we don’t see a nice clean sawtooth graph, it’s actually rather jagged. To explain that lets look at the process it’s graphing.
Data is sqooped into HDFS from a standard RDBMS; it’s then processed in Hive, and finally we perform an insert overwrite into the production Hive table. But this graph is generated using Impala, the interface that our BI tool uses. In order for Impala to know about changed data in a Hive table, you need to perform a refresh to update the catalog server’s records. Since the Impala refresh command is out of sync with the imports, we get a jagged sawtooth graph.
But a few times a day you get something worse than that jagged sawtooth graph. A few times a day the refresh command will run during the Hive import. This causes bad things to happen.
Whilst the insert overwrite command in Hive is atomic as far as Hive clients are concerned, the file movement into the production area on HDFS can take a few minutes. So if the Impala refresh command runs during the Hive insert, it will only pick up files that have actually been written - which might be just the very first file, with data from the first few years of the company’s history.
And this is the dirty secret. Whilst you can read HDFS data using Hive, Spark, Impala, Pig, etc. Unless you’re using the same tool as the writer, you’re bound to hit this sort of problem pretty frequently.
So how do we resolve it?
Well, the first and obvious option is to use a single tool. Migrate all your pipelines to the same tool that your users read data through - Spark or Impala would be a good choice. Except Spark is hard for end-users and BI tools to use, and Impala means lots of SQL which is hard to unit test. Plus people in finance like SQL, whereas data scientists like R and Spark.
The other option is to copy all of your data into a second storage location, using whatever tool the users use. We’re doing this in limited cases, and it comes with other benefits too. For instance, queries over the past 12 months work well on Parquet files with large partitions whereas the regular moving in and out of small amounts of data works well with smaller partitions and RCfiles.
Cloudera have come up with another option recently, a workflow involving views to flip between tables. It largely depends on using Impala for both read and write, but could be extended to use a combination of tools if necessary. It’s a considerable amount of complication to what should be a simple process though.
Finally, if all we cared about was generating this graph then we could just emit the value when the pipeline runs. There are cases where this makes sense, but users generally care about having the full data rather than a single graph.
In truth, none of these options are perfect. But a combination of them is where we are planning on heading over the coming months.
Of course there is the option of doing nothing - only give your users access to data which isn’t changing, e.g. yesterday’s data. But isn’t the whole point of Hadoop that you can give more real-time access to all this wonderful data?