CSI Skybet
A tale of football, nodejs, and rabbits.
With the new football season coming up, I thought it might be interesting to look at a problem that occurred near the end of last season, and the diagnostic process as I worked with the support team to track down the root cause.

My tale begins in the early afternoon of May 30th. The football season is in its final throes and I am providing on-site engineering support.
At SB&G we have a solid support model for key times where we have not only our 24 hour support desk and tech ops team on-site, but also devops engineers from key business areas, software engineers from each tribe, and a senior member of the team to act as ‘Incident Commander’ and coordinate efforts around any live issue.
Not long after I arrive on site for the 3pm kickoffs, our service desk highlight a new alarm in the monitoring system.
“Critical alarm - memory usage on dataProcessingNode06” (not an actual hostname)
Not something that I want to see - I might need to be on top of this all afternoon to maintain site stability. Fortunately we have some time before the matches kick off, so there is a bit of breathing space and I log on to the host to check it out whilst the devop engineer checks to see if it is affecting the scoreboards on the front end.
“Why’s the RAM gone?”
So what is consuming all the memory?
A quick ps auxw reveals a specific process at 80% memory usage.
node (scoreboard-football)
This nodejs process combines various different feeds of data to provide our live scoreboards. Clearly this is a problem with high-profile football imminent. The process logs don’t show any particular error that I can dig deeper into at the moment, and we need to get through the afternoon’s football. It happens that the process is designed to be restarted when necessary - so a quick discussion with the support team results in a process restart via supervisord.
Memory usage drops to normal levels, and all is well.
“But, why’s the RAM gone?”
Now we have a bit more room to look back and see what’s going on. Looking at the recent history of memory usage, it seems that memory usage has been fairly steadily increasing - and worryingly, although it has reduced, it is continuing to climb steadily.. so we’ll probably need to deal with this issue again at some point. The team agree to monitor usage levels and restart the process again a few minutes before kickoff if necessary, and possibly again at half time.
“Why now?”
Aha - this has been happening steadily since Thursday, but it hasn’t been raised before now; probably just due to the increased vigilance on a busy Saturday.
So that sounds really bad, but fortunately what has been occurring over that time is that the kernel has been killing the process automatically due to the high memory consumption - this is both reassuring, since it means that we have likely had little or no customer effect from the problem, and concerning, because no-one appears to have noticed.
“So what happened on Thursday?”
That particular host is configured and managed by chef cookbooks. So did chef-client run on that host on Thursday? No: so the configuration of the host has not changed.
Meanwhile - a second host has alarmed on memory usage. This new host is a development machine that receives the same feed. This points the finger squarely at the either the code or the data being processed. The devops engineer dutifully restarts the process, whilst I continue my analysis.
Was there a code release? Yes. Okay, so I have a suspect to cross-examine - we have the tags in git and can examine the difference in code. Unfortunately, none of the changes are to do with the scoreboard processor.
It’s now just a few minutes prior to kickoff and the first host is alarming again. So restart the process to make it through the afternoon.
It’s not the code itself, could it have been something else to do with the code release? Well, a code release would also have released NPM modules that the scoreboard processor depends on. But we use NPM’s “shrink-wrap” functionality to pin the module versions to avoid problems of this kind from an unexpected module upgrade.
Back to the drawing board… How about the data? Has the nature of the data being passed changed?
So I’m trawling back through the logs looking for a change to something that happened on Thursday. There’s nothing that looks unusual, or even changed, but all the periods of high data throughput correspond with a proportional increase in memory usage - so it’s data related.
Football happens, goals were scored, some teams footballed harder than other teams, and we made it through the day without any service impact. So we restart the processes again to leave things in a reasonable state and plan to revisit the problem with the full engineering team on Monday morning.
Who hates Mondays?
Come Monday morning, nothing has broken in the meantime. But this mystery memory consumption is still happening. I pick up the problem, and discuss possible causes with various colleagues. The diagnostic process is obviously less frantic now, and I can consult opinions from all over.
I talk through the on-site diagnostics and theories with several of my colleagues when it strikes me that the two hosts were behaving very similarly, so I compare the memory usage between the processes on the affected hosts.
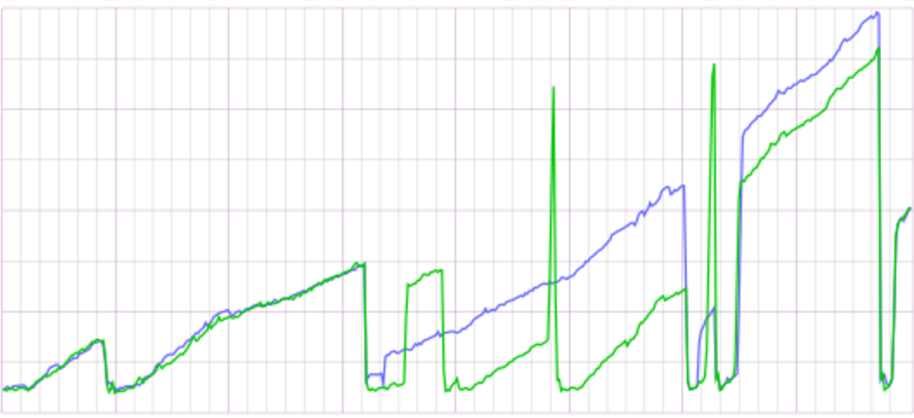
Interestingly, apart from a few areas of variation, they are in step - so it really must be a data issue. I manually examine the code and step through line by line to determine the data path, and compare with the live configuration to work out exactly what’s going on… suddenly we are getting somewhere.
And here’s the rabbit…

No, not that one, this one:
![]()
The scoreboard processor publishes updates to a rabbitmq exchange in order to push these updates to customers on pages displaying those scoreboards via an active websocket.
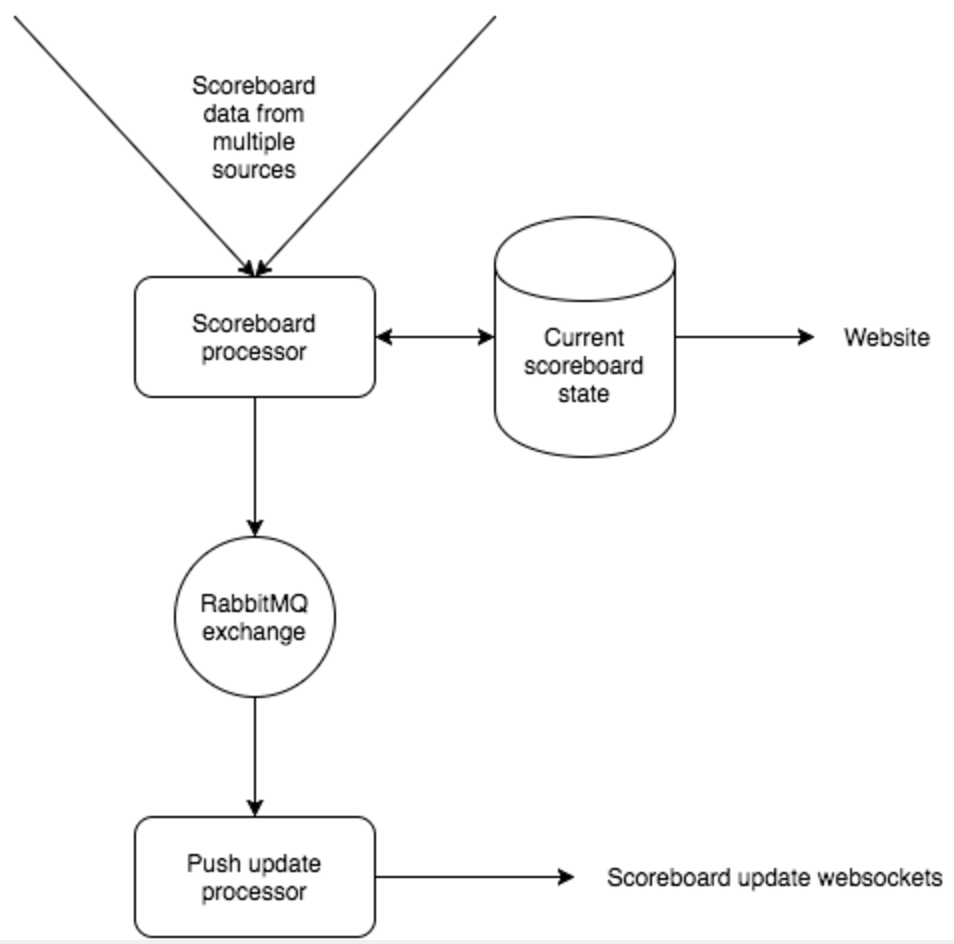
The live hosts publish to 4 downstream rabbitmq hosts, two for the live service and two to propagate the data to a proof of concept test hosted in AWS. But we turned that off last Tuesday! Now I have possible smoking gun.
At this point, we weren’t entirely sure why this would result in high memory usage, but we could confirm whether this is the problem with a diagnostic change. If we change one of the hosts to remove the POC rabbitmq from the process configuration, and restart it. Also restarting the process on the other host to get a baseline.
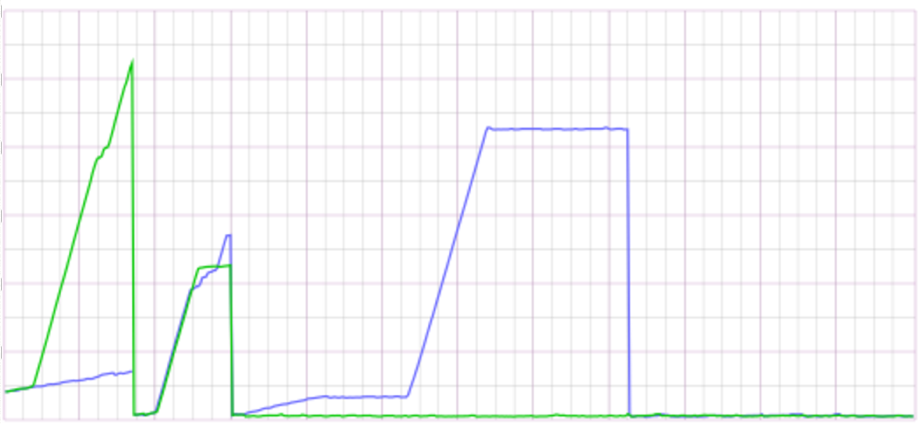
Okay - that’s positive, the green line is the reconfigured host, and it’s more healthy. It looks like we have a positive match on the slug from the smoking gun.
As we had identified the cause of the issue, we also checked the downstream rabbitmqhosts and cleared the millions of undelivered messages that we found there (resulting in the flatline on the blue line) before restarting the processes one final time.
But why does this cause high memory usage?
So, as I mentioned before, the downstream rabbitmq hosts were maintaining message queues with millions of undelivered messages. If you know anything about rabbitmq, you’ll know that that’s really bad thing. Rabbitmq performs in unexpected ways when it has a large number of undelivered messages on its queues.

But surely those messages have a TTL?
That’s true, but rabbitmq also behaves in a non-intuitive way when it comes to TTL. The queues in question are “durable”, so that if the consuming process restarts we don’t lose any messages. In this case, the consumers have been disabled so the messages are continually building up. Rabbitmq only checks the TTL on a message when it is delivering to the consumer - this avoids the need to periodically check the TTL of the messages in the queue, but does mean that a queue with no consumer will only ever get cleared by manual intervention.
Aren’t the rabbitmq hosts monitored?
Yes they are. However, the alarms were downtimed in our monitoring system because the POC had been stopped. In hindsight, these checks should not have been downtimed - the correct resolution would have been to delete the unused queues.
But why did this cause an increase in memory usage?
The Nodejs process can connect to rabbitmq successfully - those hosts are running, even if they aren’t healthy. Then when the process attempts to publish asynchronously to rabbitmq the message delivery is unsuccessful because rabbitmq will not accept any more messages. In order to maintain message ordering the nodejs amqp module then stores the pending messages in an in-memory queue for delivery when rabbitmq starts accepting messages again, hence the rising memory usage.
Hang on, back up a minute. The AWS POC was disabled on Tuesday, but the memory problems did not manifest until Thursday.
This is due to the fact that it took a few days for the number of messages to back up to the point where rabbitmq stopped accepting new messages.
Fixing it properly
Of course, the diagnostic change, whilst it confirmed what the problem was, is not a permanent fix. So our chef recipes needed tweaking, testing and running on the live hosts, as well as the rabbit queues being correctly deleted and not just purged from those hosts.
Conclusion and a moral
Our on-site support model works well, the team working closely together to resolve or mitigate live issues as they happen; sharing responsibility for the overall stability of the site. The final analysis and fixes had all been applied by the time we had our weekend support review on Monday, so we were able to discuss the problem and the fixes in order to communicate our findings to other teams.
As it happens, the football scoreboard process wasn’t the only thing affected by this problem, other processes on the same hosts also showed increasing memory usage - but they weren’t particularly noted at the time because their increase was at a lower rate due to a lower message throughput. Another host dealing with other kinds of messages was also affected, but had more base memory available to it so never got into a alarm state.
So the moral is - don’t downtime checks because a service has been decommissioned.