Fixing Agile in International Data Engineering
We’ve had a good few sprints! Our squad has maintained a consistent velocity, pushed multiple releases out every week and had few-to-no bugs reported, sprint on sprint.
It’s quite a change from last year. We had burndown charts that headed up and to the right. We had stories that took several sprints to complete. Despite having a small squad of smart, motivated people we weren’t doing so well at this agile thing.
Having delivered our commitment for several sprints now, this seems like a good moment to pause and recap a few of the things we did that seemed to move us forward. First, we need to show that we actually improved. Let’s take a look at some metrics over the last 20 sprints.
Sprint #2
This was one of the earliest sprints that we used Jira for. Previous sprints were all done on a physical board without anyone making consistent notes about performance, so their metrics are lost forever.
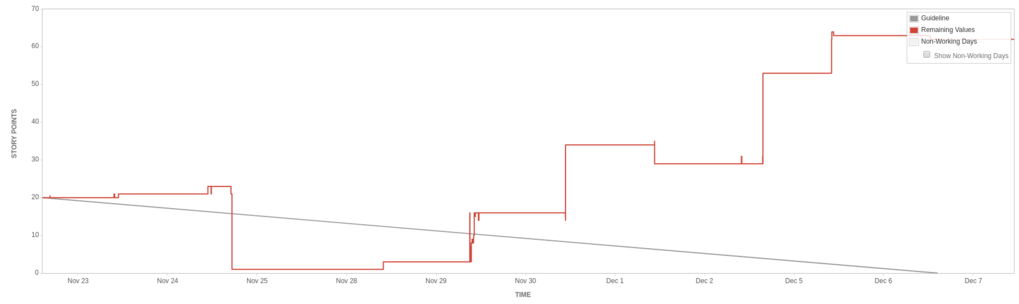 November 2016 - The Up-Burndown
November 2016 - The Up-Burndown
So what were we doing here?
- We were running planning meetings that would last up to an hour.
- We ran retrospectives but we didn’t record what we said.
- We cleared a grand total of 5.5 story points.
- We had two 20-pointers and numerous 1-2 point stories that carried forward.
- Standups often lasted 15 minutes or more (for a team of 5).
- The occasional big delivery was actually long-running stories that finally cleared.
- We had a part-time product owner and scrum master.
Sprint #8
We were running two week sprints, so this sprint took place twelve weeks later.
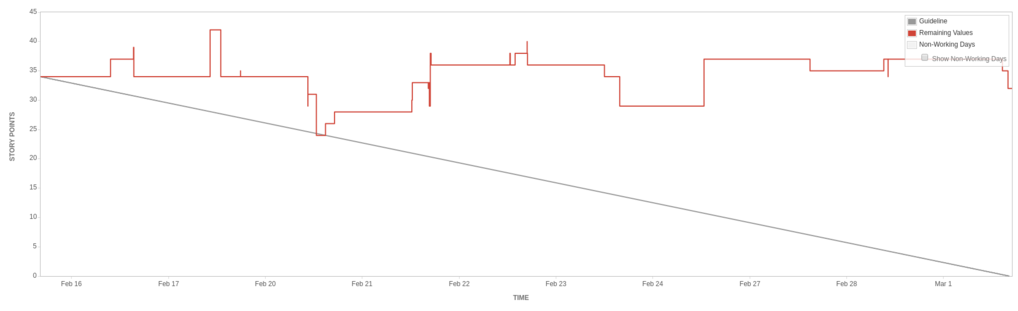 February 2017 - The Flatline
February 2017 - The Flatline
Sprints in between were not dissimilar. Burndowns either looked like cliffs, went up instead of down, or flatlined across the sprint. Nothing much had changed in what we did. We would sometimes go two weeks without putting anything into production.
I felt we could do better if we committed more to scrum, and the rest of the squad bought into giving that a try. Around this point our product owner moved on so one of us had to step up to that role. Our scrum master was about to become the Tribe’s Agile Delivery Manager, so we decided to take the scrum master role into the squad too, taking coaching and spot-checks from our ex-scrum master. As I was squad lead by this point, I took on those jobs and starting reading up!
A few sprints later…
Sprint #14
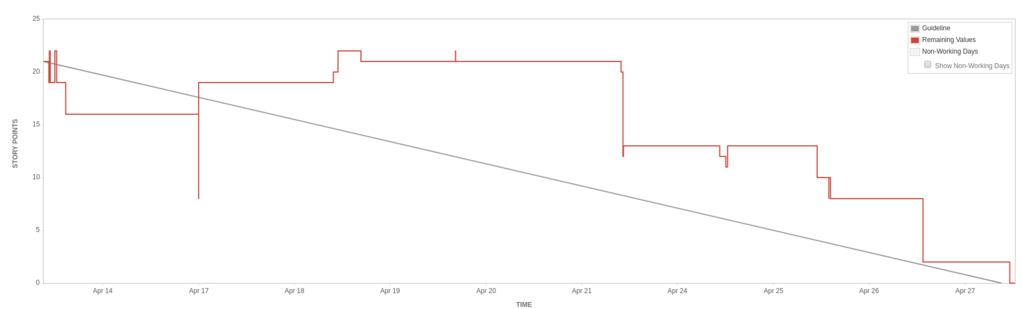 April 2017 - Heading in the Right Direction
April 2017 - Heading in the Right Direction
I think it’s fair to say our burndown charts started heading in the right direction.
Down.
We’d started making changes, and the evidence suggests they were making a difference.
- Planning was taking longer, up to a couple of hours.
- We learnt how to use subtasks and epics for better sprint metrics in Jira.
- Retrospectives were producing stories that made it into the next sprint.
- Standups went right-to-left across the board, and we started “swarming” on in-play tickets.
- Standups were lasting less than five minutes and didn’t often divert off into discussion.
- We were clearing our commitment in each sprint.
- We started using “ideal engineering days” as a points measure (1 ideal engineering day == 2 points).
- We started aiming for our task estimates to be two points at most.
I think a fundamental change that enabled improvement is that we stopped trying to go fast. We’d started trying to be predictable. That led us to spend more time planning, to explicitly commit to deliver what we’d planned, and then to pay a little more attention to metrics.
Aiming for predictability also meant we had to introduce “buffer” as part of planning. We’d look at how many points we cleared in the previous sprint and commit to 20% less than that for the next. Buffer means that instead of missing our commitment, we normally bring work into sprint towards the end and slightly over-deliver, so our velocity started to naturally stabilise. It meant we could deliver what we’d committed to, even given the inevitable estimation error and random tasks that always pop up mid-sprint. Much better!
Using “ideal engineering days” and limiting our ticket points helped us plan in more detail and identify tasks we hadn’t really understood or looked at in enough detail. It also meant that tickets moved across the Jira board much more quickly than they had before, which helped identify work that had become stuck.
Delivering our commitment meant much more positive feelings in the squad as we closed each sprint. That helped improve the mood as we went into retrospectives and planning, which made it easier to invest more time in those ceremonies to get another good sprint together. We also started celebrating end of sprint by doing our retrospective over lunch in a local eating establishment. Sky Betting and Gaming encourages squads to do this kind of thing and although it’s tough to measure, I think getting out of the office helps establish a rhythm to the sprints and build relationships and understanding between squad members.
Sprint #20
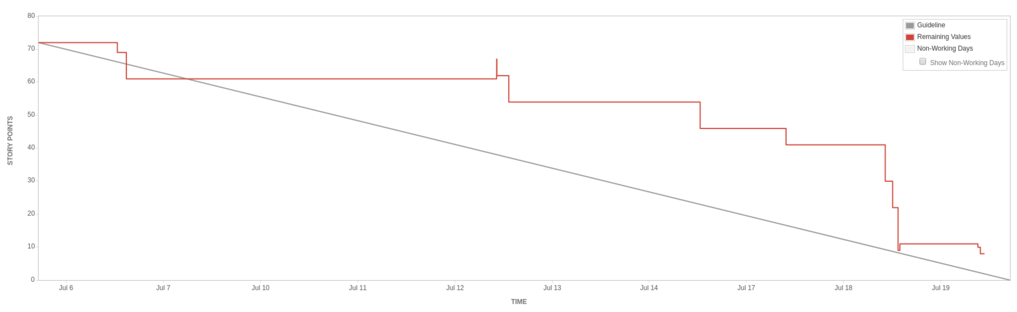 July 2017 - Looks mostly like a Burndown
July 2017 - Looks mostly like a Burndown
This is our most recent sprint. We hit some difficult technical problems that held us up, and forgot to account for a company offsite when we planned. We didn’t quite make our commitment (there’s only so much buffer can do!) but we shipped the last story in the first day of the following sprint.
Looking back over the past few months, we’ve put changes into production every single week. We rarely deliver pure technical debt or infrastructure changes, so I think it’s fair to say that pretty much every release puts some value into someone’s hands.
The sprint before had involved a mammoth four hour planning session. We had one large and important deliverable that involved changes in several components. Even with all that planning, we still ran into difficulties when an AWS issue stopped us clearing completed work out of our release pipeline! The detailed planning did help make sure everyone understood what was going on, so we were able to work around the problem with a quick re-plan. It chewed up all our buffer and took a couple of hours of overtime, but the stories we’d committed to went into production on time.
Cycle Times
Burndown charts only tell part of the story. Our control chart over the past six months tells us how quickly we’ve been getting tickets done.
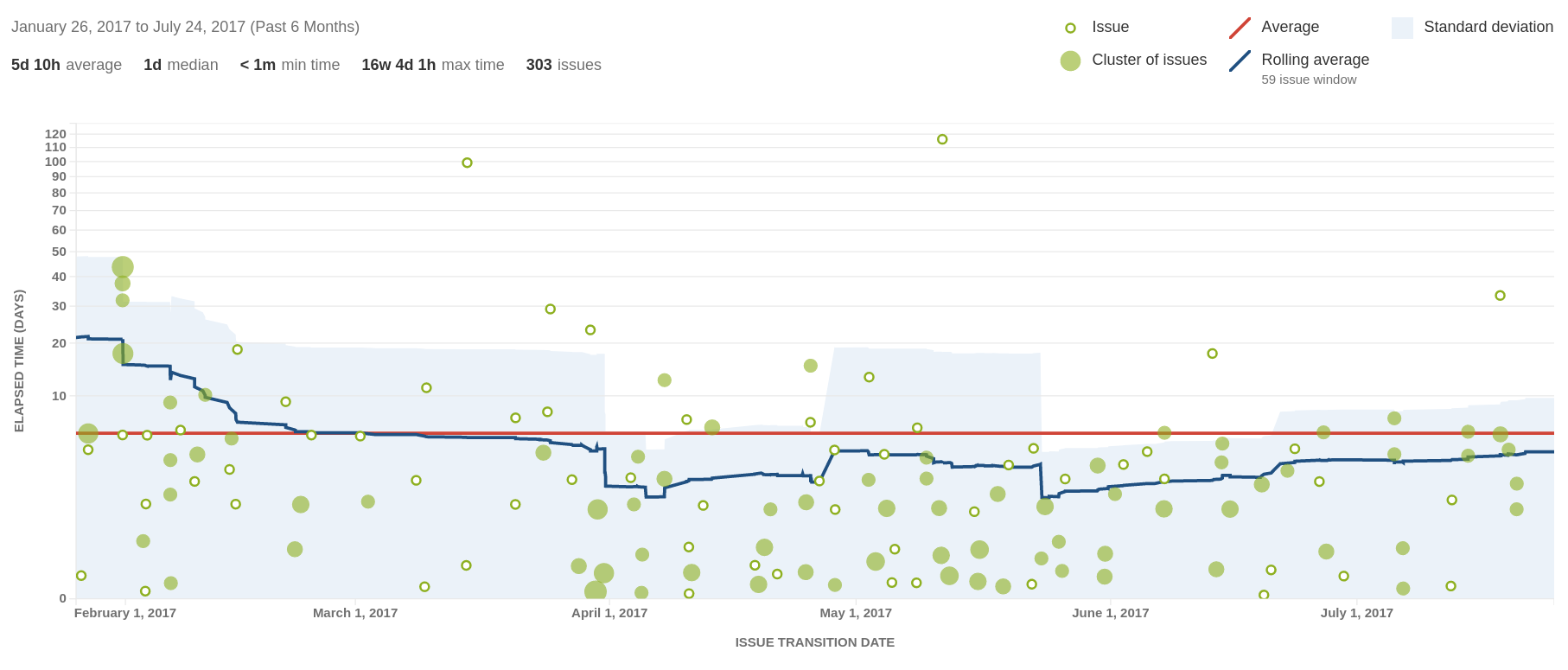 Ticket Cycle Times, Last 6 Months
Ticket Cycle Times, Last 6 Months
Given that the y-axis is a logarithmic scale, we can see some of those early, long running tickets spending nearly 120 days in sprint before being cleared. Variability in elapsed time has reduced. Although we’ve had the average cycle time down to around 1.5 days, we’re creeping back up. I guess that goes to show that you need to keep an eye on your metrics even when things seem to be going well!
Jira Reports
The burndown and control charts came from Jira. That’s right, Jira does reports, but it’s an easy feature to miss.
 Jira Reports
Jira Reports
Access reports by clicking on the icon circled in the screenshot above. Choose your report from the drop-down that says “Control Chart” in the screenshot.
In Summary
We hope that sharing our story helps others who may be struggling. The things we tried that seemed to help us achieve a consistent velocity, reduce cycle time, improve squad morale and deliver our commitments include:
- Aiming to be predictable instead of fast
- Strictly taking only the points that velocity and buffer allow into sprint
- Ensuring that squad members confirm that they can personally commit to the sprint
- Staying in planning until everyone really can commit
- Taking important agile roles like Product Owner and Scrum Master into the squad full-time
- Switching from physical boards to Jira to track metrics
- Learning how to use Jira better and ensuring that the board is up to date
- Ensuring that we account for holiday and other absence in the upcoming sprint
- Planning “buffer” time at 20% of points total
- Working right-to-left and swarming in standups
- Using “ideal engineering days” as a points measure
- Investing more time and effort in planning to break down to smaller tickets
- Aiming for ticket sizes of 1-2 points
- Max ticket size of 5 points, paying more attention in standups to those larger tickets
- Paying attention to and reacting to our burndown and cycle times
Many of the things we tried came from a book I used as reference, The Art of Agile Development. Whilst there was plenty of good advice available from a agile experts in the office, I found it useful to have all that advice in one place that I could read at my own pace and refer back to over time.
Things we haven’t tried yet but we’ve thought about:
- WIP limits to more actively encourage swarming
- Shorten sprints to one week to break up the longer planning sessions