An Exploration of Our Serverless Architecture
In a previous blog post I discussed our in-house trading engine and explained a range of benefits we have received since migrating it into the cloud, specifically to Amazon Web Services (AWS) and making use of a serverless architecture. Some conversations I have had recently highlighted how some people are unsure of how they can make use of a serverless architecture and that most often a migration to the cloud is done with a lift and shift approach. Whilst there are valid reasons to migrate from your own servers to servers in the cloud, it is not always the most cost effective solution. In this post I will explain our previous architecture, give an overview of our new architecture and explain how we have made us of some AWS native services.
The Previous Architecture
The application that we migrated to the cloud is a web application that was originally hosted on our own servers. It comprised of a Java backend, a Node backend with a web server, a React frontend and a MySQL database. We also made use of Rabbit to send data from the Java application to the Node application and Kafka was used at the boundaries of our estate for us to output our data for another system to work with. Each one of these components meant provisioning multiple servers meaning we had quite a few that required regular patching and maintenance. Since this is the application we planned to move to the cloud, by choosing a serverless approach we would no longer need to deal with server maintenance, management and specific licenses. The image below illustrates the architecture of this application.
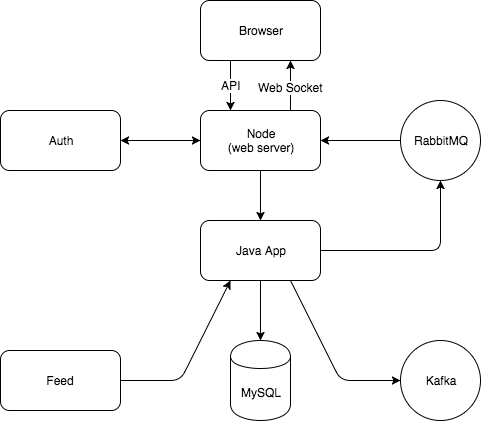 A diagram of our previous architecture.
A diagram of our previous architecture.
The New Architecture
Our new application follows a microservice approach and uses Functions as a Service (FaaS) meaning we have many more components to be deployed, each one much smaller and more loosely coupled than in our previous application. The system diagram below serves to show just how many more services we have and all of those within the centre box are hosted in AWS.
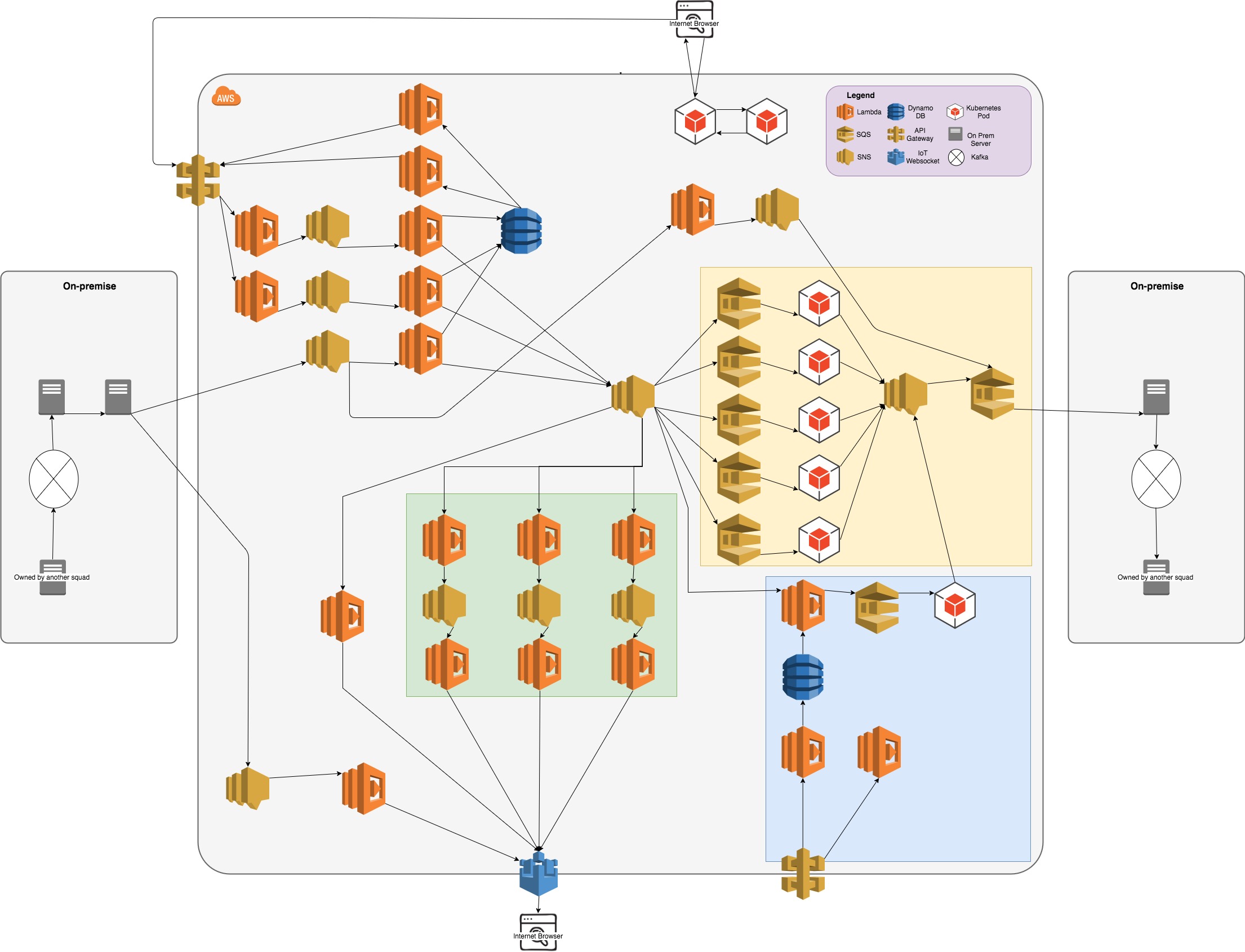 A diagram showing the architecture of our serverless solution (labels redacted).
A diagram showing the architecture of our serverless solution (labels redacted).
At a high level our application is driven by data from feeds, and inputs from users via a web browser. The JSON data we receive via feeds is sent to an on-premises Kafka topic by another squad’s application and we then send it into our AWS environment. Within AWS this data is used by numerous, separately deployed functions to either store it, mutate it or generate new data such as odds and prices for skybet.com. Each of these functions are decoupled by AWS queueing and notification services. Once our system is finished creating the data required it is put on a queue in AWS and our on-premises services poll for the data to pass on to the next squad’s services, or sent to any browser using the web application through a websocket. For user inputs the path is fairly similar with the exception of data enters our AWS estate through an API.
The Services We Use
API Gateway
API Gateway is a managed service that allows you to create APIs and provide access to your other services and functionality. By using API Gateway we did not have to specifically code API endpoints like we did previously in our Node and Java applications; instead the endpoints are simply declared in our Infrastructure as Code tool, Terraform. In addition to not having to manage any servers for API Gateway, AWS provide monitoring and autoscaling as standard.
Simple Notification Service (SNS)
SNS is a publish/subscribe service that allows you to subscribe multiple services to be notified of any messages received on that SNS topic. Most of our SNS topics receive data from a Lambda function and then publish that data to another Lambda function which helps decouple the behaviours in our system. Another way we have made use of SNS is for one SNS topic to receive data from multiple Lambdas and then publish that data to multiple SQS queues. The benefit to using SNS is once a message is received to a topic it immediately notifies all subscribers; this differs from some of the other services which are polled and can subject your system to polling delays.
Simple Queue Service (SQS)
SQS is a message queueing service that can be polled for new messages and like SNS, has helped us decouple our system into to smaller components with a specific task. One of the ways we have used SQS is to deliver JSON messages to our Java Spring Boot applications which are contained in Kubernetes pods (more on those later). Rather than expose these applications for a publish/subscribe solution we instead poll the SQS from the Java application; this makes our colleagues in security much happier.
Lambda
AWS Lambda falls into the category of Function as a Service. It is a managed service that allows you to upload code to the cloud and then run it without having to provision any servers. Lambda scales automatically and is redundant across multiple availability zones by default. You can set up triggers which will execute the Lambda function, something we have made extensive use of. Some of the functions we have created are invoked in response to API Gateway calls, typically these functions either process data from the API request and then store it in a database or query one of our database tables to serve data back to the frontend. Given the nature of Lambda it naturally enables decoupled components with a single purpose. This is clear in our design as we have several Lambda functions in our architecture, most of which are triggered by SNS. These functions are often performing a specific task using JSON data and then passing on the outcome to another SNS topic or storing it in a database.
Internet of Things (IOT)
IOT is usually associated with connecting a device to the cloud such as a button, a lightbulb or a thermostat. For our system we made use of IOT’s support of the MQTT protocol over websocket so that we could publish JSON data to an IOT topic and have our React frontend subscribe to it. This allows our web application users to receive updates without the need to refresh the page.
DynamoDB
DynamoDB is the NoSQL database offering from AWS. As with other serverless offerings from AWS it is fully managed, handles auto scaling (if configured to) and to create a new table we simply add a number of lines to our Terraform code. DynamoDB integrates well with Lambda and we have several Lambdas that read from and write to DynamoDB tables that we have created.
Kubernetes
Technically you could say I am cheating by including Kubernetes in my explanation of our serverless system since our Kubernetes solution runs on AWS EC2 instances which have to be provisioned, albeit not quite in the same way as building servers for our own data centers. The Kubernetes platform is provided by the Bet Platform Engineering squad within Sky Betting & Gaming so for other squads, like the one I work in, it is a serverless solution as we do not handle the provisioning or managing of the EC2 instances ourselves. We use Kubernetes as there are some parts of our application that are better suited to long standing processes (Lambda functions have a limit of 300 seconds) so we have created small, Spring Boot Java applications. As mentioned previously these applications poll SQS for new messages so they can carry out the processing required and then send their data to one SNS topic for other services to make use of. Since hosting our frontend in an S3 bucket as a static website was unsuitable, we also deploy our UI to Kubernetes.
Hopefully this post helped explain how you too can make use of serverless services in AWS. It does require a bit of a shift in how you think when designing the architecture but as discussed in my previous post we have seen many benefits. Look out for my next post where I will cover some of the challenges we have come up against and the solutions we used to solve the problem.