QCon London
So, this year I used my Tech Ninja Fund to go along to QCon London. For the uninitiated, QCon is a global software engineering conference run by the same folk who produce infoq.com (an excellent website which I’ve used for years to keep up with new tech and trends).
About one and a half thousand people rocked up to the QEII Conference Centre in London back in March, and spent a few days listening to about 140 speakers from across the tech world talking about what’s new. There’s always a great mixture of tech giants like Netflix and Google, smaller-scale innovators like Sysdig and BoxFuse, and independent gurus, experts and academics all contributing to the mental deluge of ideas and perspectives. Combined with the facilitated collaboration sessions, workshops, and lots of opportunities to meet new people, it really does leave you feeling bewildered but inspired with new ideas and viewpoints.
Anyway, here’s an overview of some of the stuff I saw.
Unevenly distributed
Adrian Colyer, (previous CTO of Applications for VMWare, and also of SpringSource), publishes a blog in which he summarises an academic paper each weekday. His keynote presentation on Day 1, about why we should love papers, was a whistle-stop tour of some of them. (In case you’re wondering, the title Unevenly Distributed is from William Gibson: “The future is already here — it’s just not very evenly distributed”)
Of stand out interest to me was his guide to some of the up and coming developments in hardware and networking:
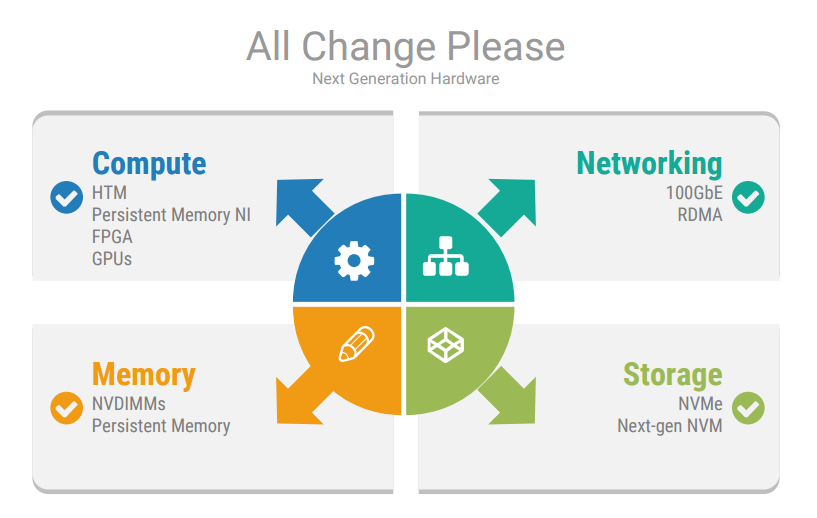
- 100Gb Ethernet
- RDMA (Remote Dynamic Memory Access). This allows memory in any host on a network to be accessed by another host without requiring its CPU (all done through the network card) resulting in blisteringly fast performance.
- Non-Volatile RAM. Blurring the lines between memory and storage, NVDIMMS and distributed UPS both use a battery or capacitor to ensure enough power to persist to NAND Flash in case of failure. All the performance benefits of DRAM, plus persistence.
- HTM (Hardware Transactional Memory), available in the x86 instruction set architecture since Haswell.
- FPGAs (Field Programmable Gate Arrays). Intel will soon start shipping Xeon chips with integrated FPGAs (talking over Intel’s QPI interconnect), which will be highly suited to efficiently handling big data workloads in an energy efficient way. These will be available on AWS EC2 soon as well.
Combining these technologies has some pretty far reaching implications for how we design our architectures in the future. Our traditional notions of IO and networking being bottlenecks might become a thing of the past, with CPU and choice of algorithm demanding our focus instead. Take for example a system which Adrian has written about a couple of times, most recently back in January, called FaRM (Fast Remote Memory). It gives you distributed transactions with strict serialisability while combining high performance, low latency, durability and high availability:
A 90 machine FaRM cluster achieved 4.5 million TPC-C ‘new order’ transactions per second with a 99th percentile latency of 1.9ms. If you’re prepared to run at ‘only’ 4M tps, you can cut that latency in half. Oh, and it can recover from failure in about 60ms.
Pretty impressive stuff.
And a system called RAMCloud exploits RDMA to allow reads from anywhere in a 1000-node cluster in 5µs. Writes take 13.5µs. A system built on top of that named RIFL (Re-usable InFrastructure for Linearisability) handles distributed transactions in about 20µs. Yep, you read that correctly. 20µs.
Immutable Infrastructure
Another theme that is affecting how we think about our systems right now is containers, unikernels, and cloud. This area had its own track, and there were great talks on the subject (see Containers (In Production) on Day 2).

Axel Fontaine, of BoxFuse, gave a great talk entitled Immutable Infrastructure: Rise of the Machine Images in which he points out that we would never dream of deploying different code artifacts across our environments, and across our cluster. Neither would we think it was okay to release features by delving into a tarball and making changes to it. Our deployables are immutable, single use, cheap and disposable. So now we live in a world of abundance (“every day, AWS adds enough server capacity to power the whole $7B enterprise Amazon.com was in 2004”) why are we treating our infrastructure differently?
Henry Ford has been quoted as saying:

Here at Sky Betting & Gaming we use Chef to ensure consistent configuration across our estate, but Axel argues that Chef (and Puppet etc.) are simply a faster horse - a faster way of delving into the infrastructure equivalent of tarballs and tinkering around to try and make them all consistent.
Coining another animal-based analogy, with machine images we should now be treating our servers like cattle instead of pets. We should no longer care about individual servers, thinking of a name for them, taking them to the vet when they’re poorly. It seems to me that where we want to get to is that if a server has a problem affecting a live service, we should shoot it in the head and spawn a pristine new one.

Sky Betting & Gaming has been adopting cloud, and containerisation, for a little while now - and Axel had some helpful insights into what this means for how we design and plan our systems. Cost-driven architecture makes more sense now that we can spin up servers for a few hours when we need them and kill them off when we don’t - something which is pretty handy for a business model like Sky Betting & Gaming’s where we essentially have a Black Friday every Saturday afternoon. And now that we can start to care less about individual servers, from an operational perspective we can think about services instead: Is this service available? How is it performing across different data centres or regions? Which versions of the services are we running currently? Are we ready to start migrating traffic onto the newest release?
At design time this has implications: Operationally, we need to ensure that we automate all the things. We need health check endpoints, log shipping, dynamic monitoring. Architecturally, we need service discovery. We need statelessless. We need small, simple solutions that scale horizontally.
So in a world where we have lots of small services (maybe microservices), each potentially with their own de-normalised data store appropriate to their specific use case, how do we go about keeping our data in sync?
Staying In Sync
Martin Kleppmann made the case for one solution in his talk Staying in Sync: From Transactions to Streams. The problem essentially is that most of us no longer live in a world where we have a single monolithic application talking to a single monolithic database - at Sky Betting & Gaming we certainly don’t. Most companies have a multitude of derived data stores like caches, search indexes, recommendation engines - all those myriad data stores which support individual services.
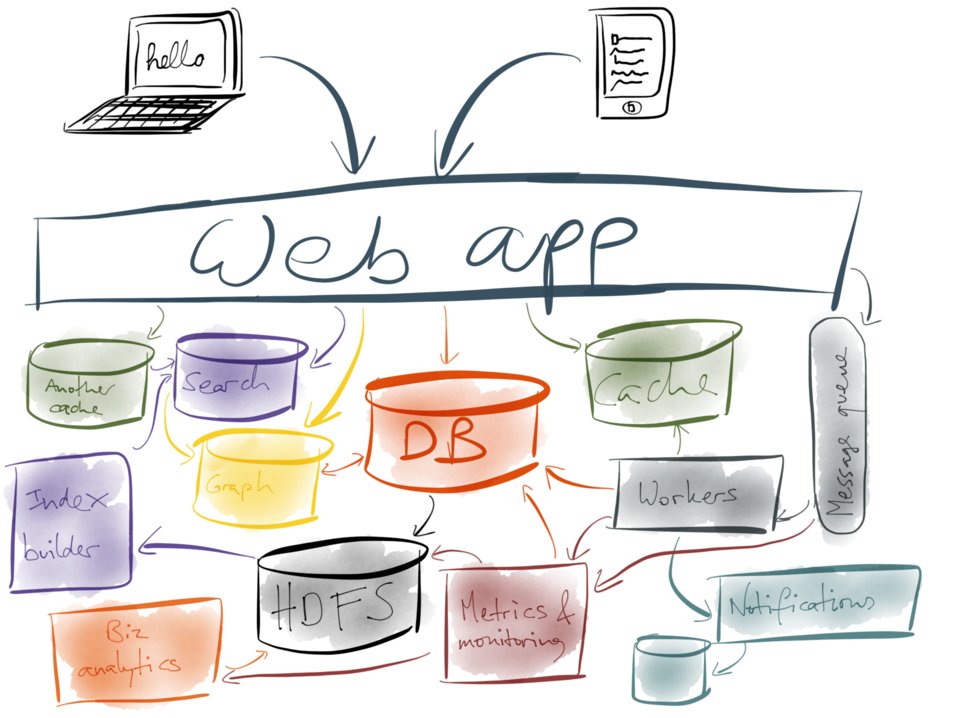
When the data changes in the “system of record” we need to update all those derived data stores, but doing that reliably is a notoriously difficult challenge due to the risk of write failures, deadlocks, updates occurring out of order and so on. One commonly used solution is the use of distributed transaction management. This has been around a while, and essentially involves introducing a central coordinator (your application + a transaction manager) whose job it is to orchestrate some kind of n-phase commit across multiple data sources. And this works fine as long as: a) The application doesn’t crash b) Nothing fails during the commit phase c) No deadlocks occur, and d) You don’t mind your system running slower because of all the locks and synchronous commits. (Typically systems run ten times slower with distributed transaction management).
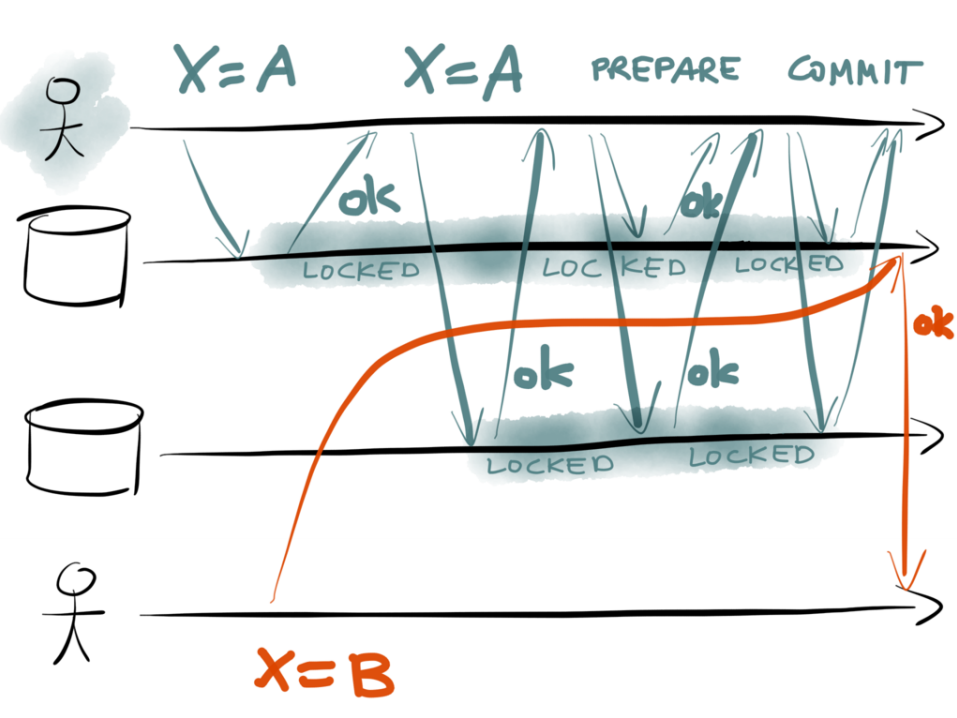
I’d argue that you very rarely need distributed transaction management - and if you do, maybe you should rethink the problem. Martin described solving the same challenges using event streams and Kafka. Essentially, instead of orchestrating multiple systems using the application, don’t orchestrate at all. Write all changes as immutable events onto an append-only log (a Kafka topic in his example). Then let all the systems that need to be kept up to date with those changes subscribe to the events and update themselves independently. Anyone familiar with CQRS and event sourcing, or database replication oplogs will recognise this.
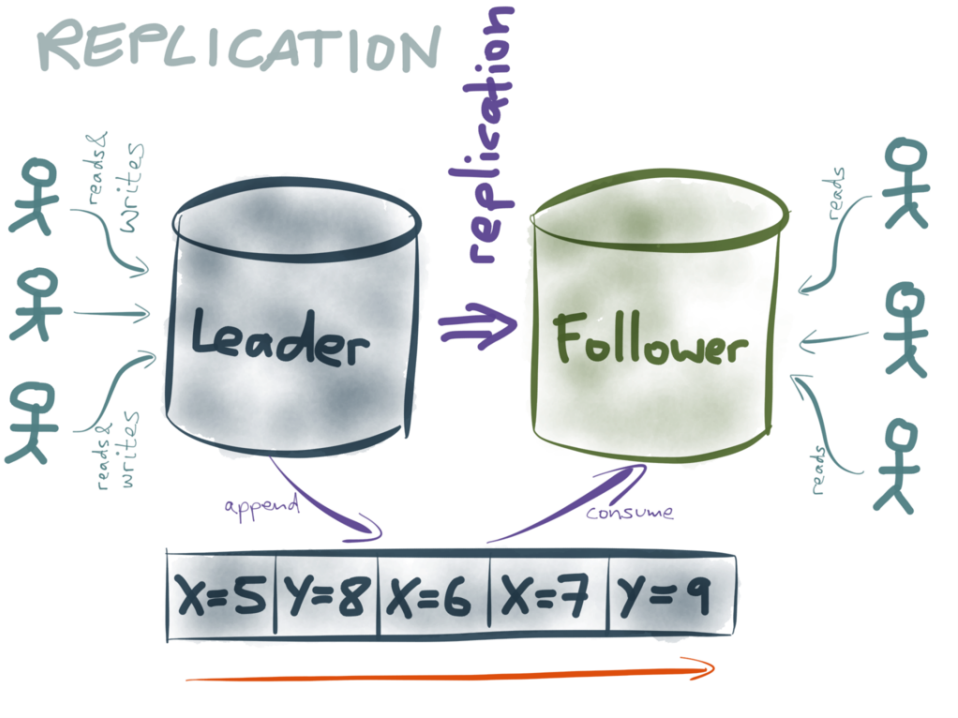
As Martin points out:
Stupidly simple solutions are the best
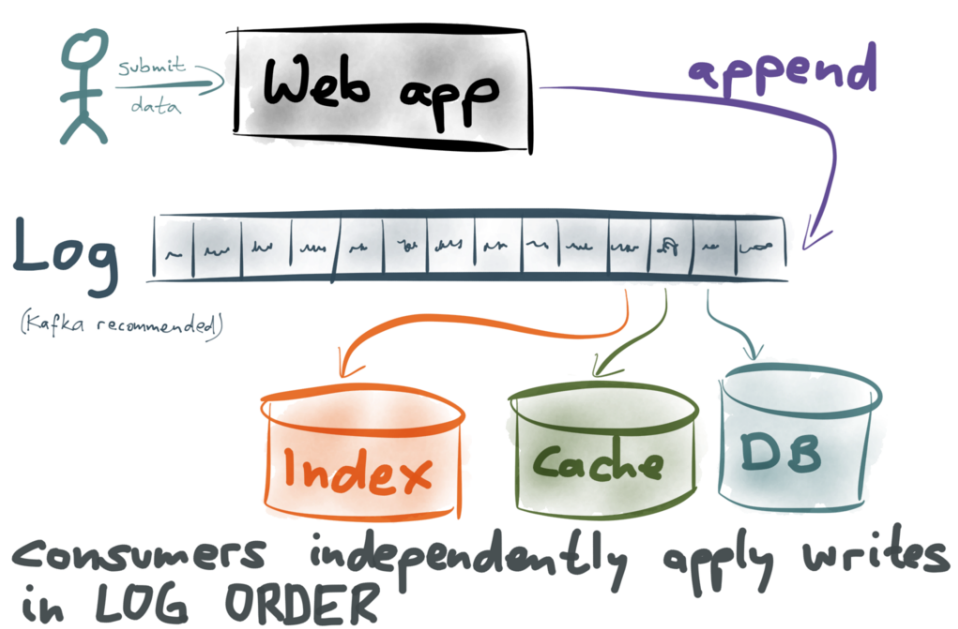
Essentially, I’d say it has the following features:
- You guarantee consistency across your data stores, because you have total ordering of events, and each consumer processes those events in a single-threaded sequential manner.
- A failure preventing the data source from reading (such as a network interruption) will only affect that consumer. Since the consumer is responsible for maintaining its own position in the log, it can pick up where it left off when the failure is corrected.
- A slower data source will take longer to update itself, so at any given point in time the data sources might not be in sync, but they will be. (This is what’s known as eventual consistency). This might not make it suitable for situations where you present data from two or more data sources next to each other on a web page for example.
- A slower data source won’t slow down updates being available in the others, in the way that transaction management would.
- Since the reliability and consistency guarantees come from the single-threaded sequential nature of the consumers, scaling is achieved by sharding the events into separate logs (Kafka topics).
- It leads to an architecture which can continue to grow without incurring large-scale technical debt, due to its loosely coupled nature. In this way, it goes nicely hand in hand with microservices should you wish to go down that route.
It’s worth noting that financial systems, famous for stringent requirements around consistency, reliability and performance, very often use this kind of model.
Failure Testing
Talking of reliability, the last talk I wanted to touch on is a hugely entertaining one I watched about fault injection testing at Netflix. In a pretty slick double act, academic Peter Alvaro and Kolton Andrus previously at Netflix, described how they met and collaborated on finding a way of discovering fault-intolerance in Netflix’s architectural estate: Monkeys in Lab Coats: Applying Failure Testing Research at Netflix.
I highly recommend watching this talk, but the core concept was this:
If you run 100 services and you’re interested in scenarios involving a single service failure, that’s quite easy to write fault injection tests for - there’s only 100 of them you need to run. But… it’s probably not very interesting, because you’ll have built redundancy in (right?), so you won’t be discovering the “deep” bugs that happen when multiple things fail.
So, how big is the space of possible failures? It’s the power set of 100, which is 2^100, or roughly 1,000,000,000,000,000,000,000,000,000,000. That’s probably not going to be a viable number of test executions. [If each execution took 1 second, it would take longer than the age of the universe to run them all. About 40 trillion times longer in fact!]
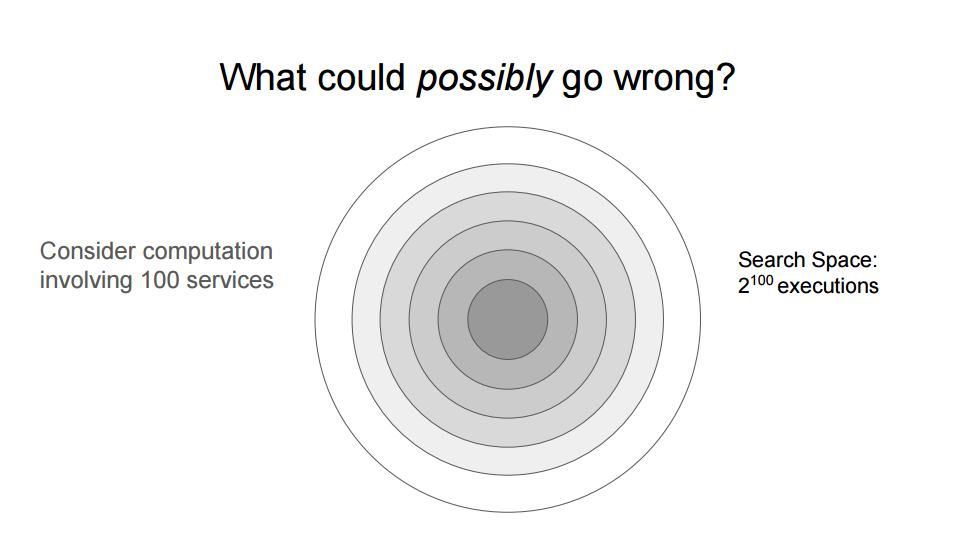
Even if you decided to only look at combinations of seven faults, that would mean a search space of 16 billion (over 500 years of continuous executions each one second in duration); even just combinations of four would be 3 million executions. This might be do-able in a month, but how much stuff changes in that month? Even then, you’re still not testing for very deep bugs.

Another approach is random testing: Switch things off at random, and hope you find some bugs. This certainly might catch some deep bugs given enough time, but the vast majority of interesting failures will remain undiscovered.
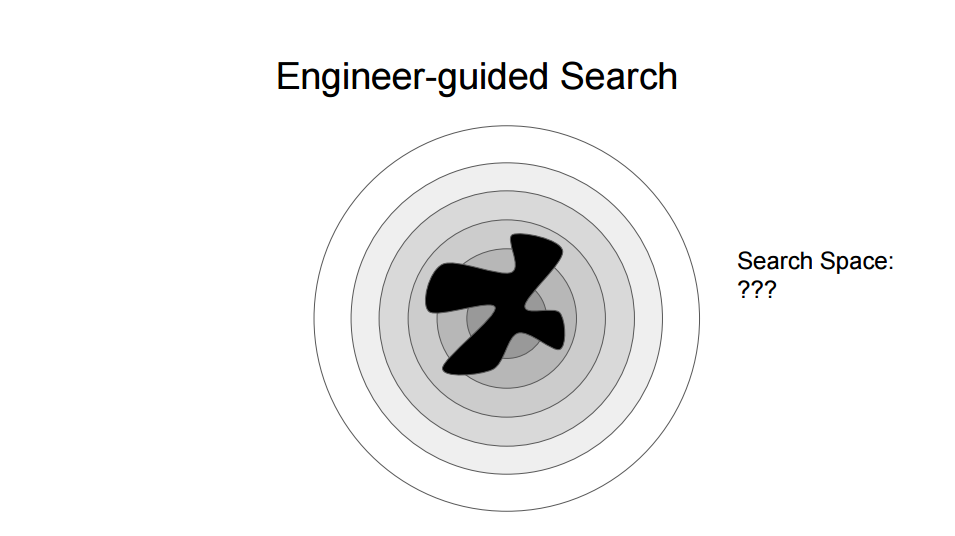
Yet another approach is what they called engineer-guided search, where you rely on the knowledge of your engineers to identify possible deep faults. This can be effective, but it’s sloooow, and inherently not automatable.
Enter Peter’s paper on Lineage Driven Fault Injection. This turned the question of “What could go wrong?” into a more directed question: Consider a good outcome and ask “Why did this good thing happen? Could we have made any wrong turns along the way?”
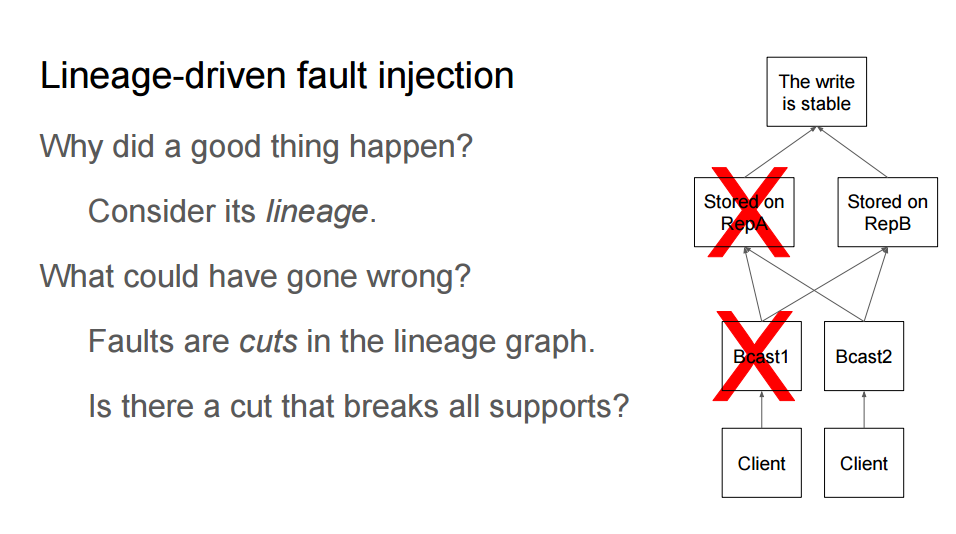 For example, consider the diagram. Each layer has redundancy, so the failures depicted don’t represent an interesting failure scenario because there’s still a path to a good outcome. However a failure in both the Bcast nodes would break all paths from leaf to root, which is more interesting.
For example, consider the diagram. Each layer has redundancy, so the failures depicted don’t represent an interesting failure scenario because there’s still a path to a good outcome. However a failure in both the Bcast nodes would break all paths from leaf to root, which is more interesting.
And so the idea that Peter and Kolton developed was one that started with the lineage of successful outcomes and from that DAG, extracted a set of trees, each of which is sufficient to produce a good outcome. For each one of those trees, breaking one step will break that path (e.g. breaking RepA or Bcast1 in the diagram).
Now the space of interesting failures can be written as a boolean formula in conjunctive normal form:
(RepA OR Bcast1) AND (RepA OR Bcast2) AND (RepB OR Bcast2) AND (RepB OR Bcast1)
…which can be offloaded to a highly efficient satisfiability server.

Now, creating those lineage graphs becomes the challenge, and Peter and Kolton started by using data available in the front-end (where they use Falcor ) to understand what the successful path was that resulted in each good outcome for a customer. And using this approach for “Netflix AppBoot”, in an architecture of around 100 services, they reduced the search space from 1,000,000,000,000,000,000,000,000,000,000 to just 200 failure scenarios, which were interesting. When they tested them, they identified six bugs which would have impacted on their customers - some of them deep bugs that would never have been found by an exhaustive enumeration strategy, or thought of by engineers.
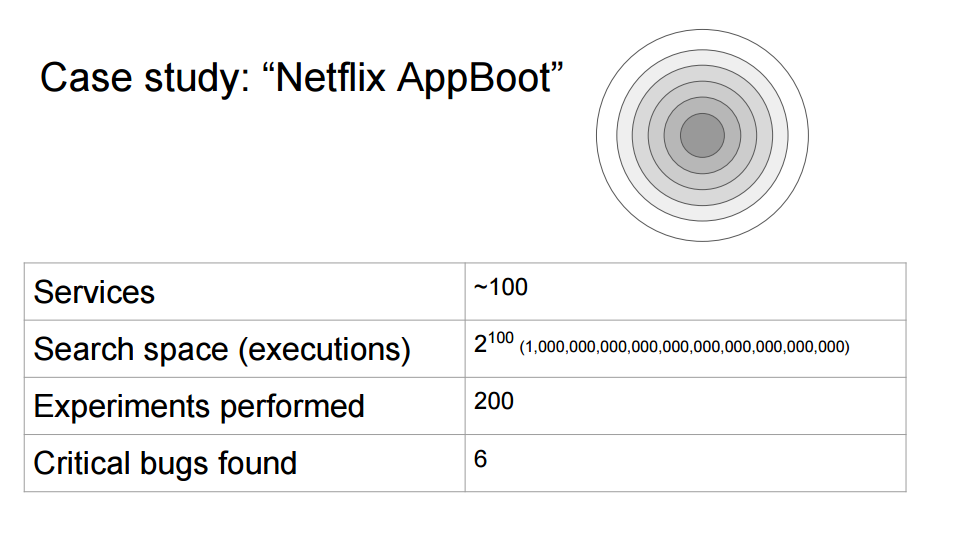
The nature of our business and architecture is very different to Netflix’s, but our Site Reliability Team are constantly looking at new and interesting ways of identifying fault injection tests across our architecture, and ideas like this make the problem manageable.
There were many many other fascinating talks at QCon which I don’t have space to go on about here (and let’s be honest, you might not have got this far anyway!), but I highly recommend checking out the videos as they become available on http://infoq.com/.