Kafka on NFS
There is a general recommendation against running Apache Kafka on NFS storage. But the Jira tickets relating to this are closed resolved, so why is this still a recommendation? Surely using NFS on a nice big NAS that our storage team provide will make our Kafka cluster for log shipping nice and easy to maintain. The logs get queued locally if Kafka is down, performance isn’t a huge concern for this cluster, and we didn’t know how much this cluster would grow over time. So using these NFS exports seemed like an easy win - cheap storage, easily expandable in the future.
Running Kafka on this NFS mount did in fact run pretty well for quite some time. Kafka is pretty stable day-to-day, and so we never had to rebalance anything or delete any topics. That is until one day when we needed to expand the cluster to add some new brokers to be better prepared for some new large topics.
Adding new Kafka brokers to an existing cluster doesn’t actually do very much. It makes the brokers available for producers and consumers, but any existing topics will continue to be partitioned across the original brokers. Our two new brokers were sitting there quietly doing very little.
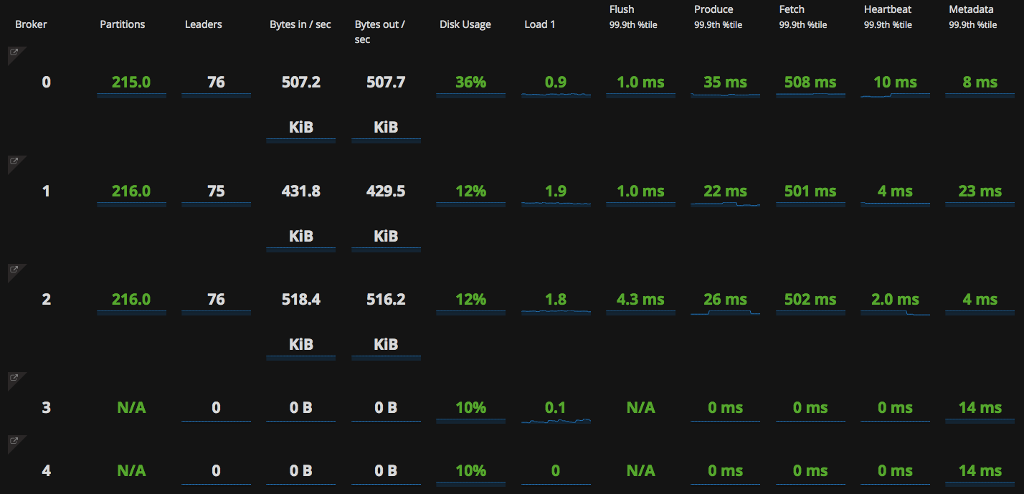
We put together a little script that would perform the reallocation of partitions across the cluster. And immediately after running this we started seeing brokers crashing with errors about deleting data:
[2018-07-04 16:01:54,059] ERROR kafka.server.LogDirFailureChannel Error while deleting log for gaming_shared_combined_logs_raw-0 in dir /kafka/logs_cluster/data/node1
Restarting the broker brings it back online, but it dies again quite quickly. So what’s happening here?
With the broker back online, the partitions that haven’t yet been re-allocated now start moving. Kafka first creates a new copy of the partition on the destination broker, and then it deletes the extra copy on the old broker. This deletion is where the crash is happening, and it’s because of the way the NFS file system works.
Most Unix file systems allow for files to be deleted whilst they are open and being written to. We talk about file deletion, but really the operating system is only unlinking the pointer to the file in the file system and marking the space on disk as available. The application writing to the file will keep the handle open, and the disk space will only be reclaimed once this file handle is closed. No errors are generated at any point in this process, it is perfectly expected behaviour.
NFS mounts behave differently. Because of the design of the NFS protocol, there is no way for a file to be deleted from the name space but still remain in use by an application. Thus NFS clients have to emulate this using what already exists in the protocol. If an open file is unlinked, an NFS client renames it to a special name that looks like “.nfsXXXXX”. This “hides” the file while it remains in use. This is known as a “silly rename.”
Directories containing these “silly rename” files cannot be deleted, and you get a device not ready error when you try. Kafka stores partitions as directories with data files inside, and it doesn’t bother freeing up the file handle before unlinking it. Which is why we get the crash. On the next start the broker knows it didn’t stop cleanly, so the first step is to re-index the data files it has on disk and remove the files and partitions it no longer needs; at this point the files are not open, and so can be cleanly deleted.
After many restarts of crashed Kafka brokers our cluster is back online and partitions are more evenly allocated.
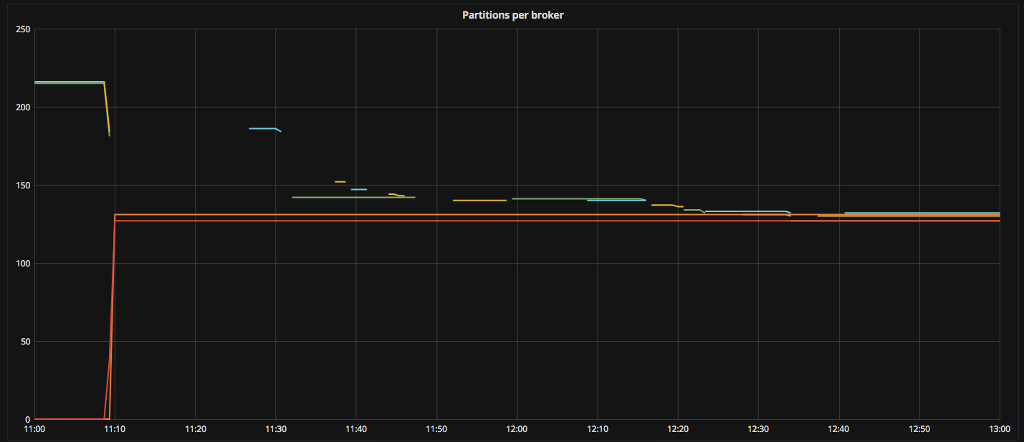
The current version of NFS is 4, and this in theory does allow for file deletion behaviour similar to other Unix file systems. However, since this would break protocol it hasn’t yet been introduced. Which means there is no way of removing topics or partitions in Kakfa on an NFS file system without seeing these crashes. The fix is to not use NFS storage for your Kafka data, as originally recommended. But at least now we know why.